 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemBART: A Pre-trained BART Model Assisting Organic Chemistry Analysis
Jan 06, 2026Recent advances in large language models (LLMs) have demonstrated transformative potential across diverse fields. While LLMs have been applied to molecular simplified molecular input line entry system (SMILES) in computer-aided synthesis planning (CASP), existing methodologies typically address single tasks, such as precursor prediction. We introduce ChemBART, a SMILES-based LLM pre-trained on chemical reactions, which enables a unified model for multiple downstream chemical tasks--achieving the paradigm of "one model, one pre-training, multiple tasks." By leveraging outputs from a mask-filling pre-training task on reaction expressions, ChemBART effectively solves a variety of chemical problems, including precursor/reagent generation, temperature-yield regression, molecular property classification, and optimizing the policy and value functions within a reinforcement learning framework, integrated with Monte Carlo tree search for multi-step synthesis route design. Unlike single-molecule pre-trained LLMs constrained to specific applications, ChemBART addresses broader chemical challenges and integrates them for comprehensive synthesis planning. Crucially, ChemBART-designed multi-step synthesis routes and reaction conditions directly inspired wet-lab validation, which confirmed shorter pathways with ~30% yield improvement over literature benchmarks. Our work validates the power of reaction-focused pre-training and showcases the broad utility of ChemBART in advancing the complete synthesis planning cycle.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
ELSR: Extreme Low-Power Super Resolution Network For Mobile Devices
Aug 31, 2022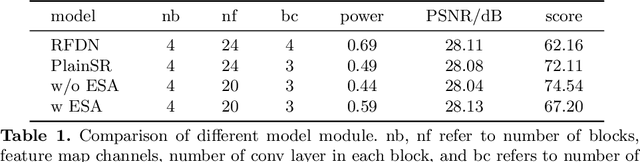
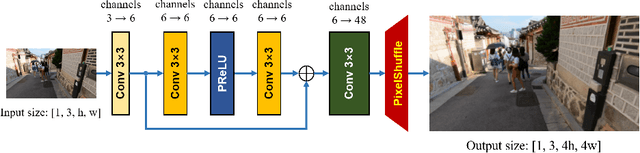
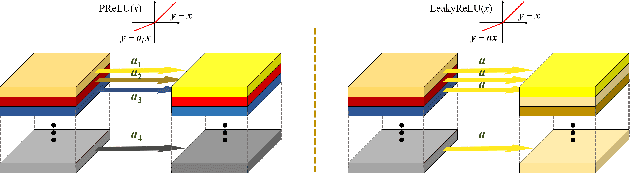

With the popularity of mobile devices, e.g., smartphone and wearable devices, lighter and faster model is crucial for the application of video super resolution. However, most previous lightweight models tend to concentrate on reducing lantency of model inference on desktop GPU, which may be not energy efficient in current mobile devices. In this paper, we proposed Extreme Low-Power Super Resolution (ELSR) network which only consumes a small amount of energy in mobile devices. Pretraining and finetuning methods are applied to boost the performance of the extremely tiny model. Extensive experiments show that our method achieves a excellent balance between restoration quality and power consumption. Finally, we achieve a competitive score of 90.9 with PSNR 27.34 dB and power 0.09 W/30FPS on the target MediaTek Dimensity 9000 plantform, ranking 1st place in the Mobile AI & AIM 2022 Real-Time Video Super-Resolution Challenge.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022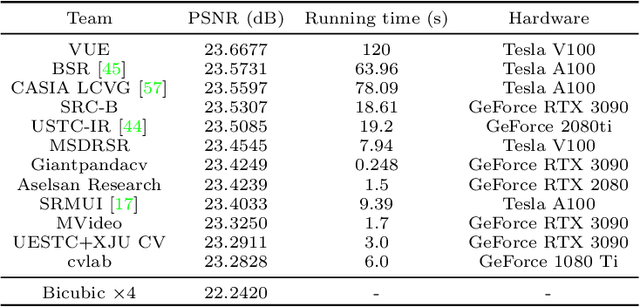
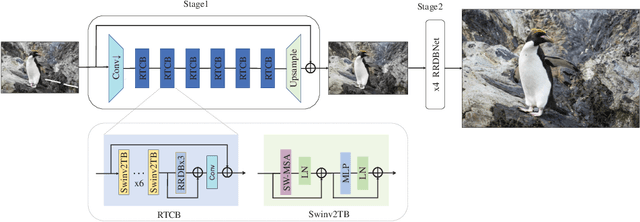

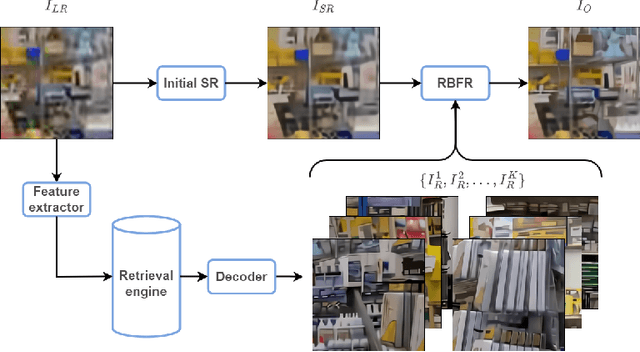
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.